
|
Chapter 13 |

|

|
|
Chapter 13 |
|
Contents:
The World Wide Web
Anonymous FTP
Finding Files
Retrieving RFCs
Mailing Lists
The White Pages
Summary
Now that our network is configured, debugged, and secure, how will we use it? Increasingly, a network serves not merely as a delivery link between two hosts, but as a path to information resources. Information servers, file repositories, databases, and information directories are available throughout the Internet. But, with millions of devices connected to the Internet, finding these services can be a daunting task.
This chapter explores various ways to avail yourself of this storehouse of information. We look at how information is retrieved from network servers, some tools that make it easier to locate that information, and how to configure your system as an anonymous FTP server.
The primary method used to retrieve network information is the World Wide Web. The Web is an interlinked network of hypertext servers based on the Hypertext Transfer Protocol (HTTP) that runs on top of TCP/IP. The Web is accessed via a browser , a program that provides a consistent graphical interface to the user. All of the popular UNIX browsers - Netscape, Mosaic, Arena, etc. - are modeled after the original Mosaic browser developed at the National Center for Supercomputer Applications (NCSA). Therefore, they share a common look and feel.
Most UNIX systems do not ship with a built-in browser; you need to download one from the Internet. The Netscape browser is available at the URL http://www.netscape.com . It can be downloaded, evaluated, and then purchased. (It's nice to be able to try before you buy!) The Mosaic browser is available free of charge at ftp://ftp.ncsa.edu/Web/Mosaic/Unix/binaries . They both work well and in an almost identical manner. However, Netscape is the most popular browser and has an active development team.
Obtaining information from hypertext Web pages is the most common use for a browser. Use yours to keep up with the most current network information. Figure 13.1 shows a network administrator checking the security alerts at the Computer Security Resource Clearinghouse at the National Institute of Standards and Technology.
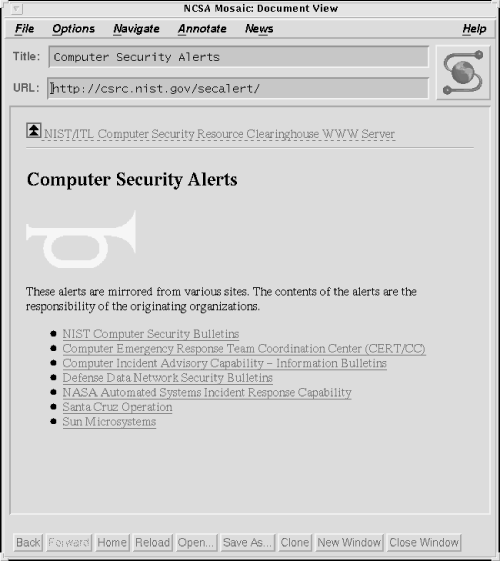
The URL field near the top of the sample screen is the location of the Web page we are reading. On some other browsers this field is labeled "Location" or "Netsite," but in all cases it performs the same function: it holds the path to the information resource. In the example the location is http://csrc.nist.gov/secalert/ . "URL" stands for universal resource locator . It is a standard way of defining a network resource and it has a specific structure:
service :// server / path / file
In the sample URL, http is the service; csrc.nist.gov is the server; and secalerts is the path to the resource contained on that server. This tells the browser to locate a host with the domain name csrc.nist.gov , and to ask it for the hypertext information located in the secalerts path. Hypertext is not the only type of information that can be retrieved by a browser. The browser is intended to provide a consistent interface to various types of network resources. HTTP is only one of the services that can be specified in a URL.
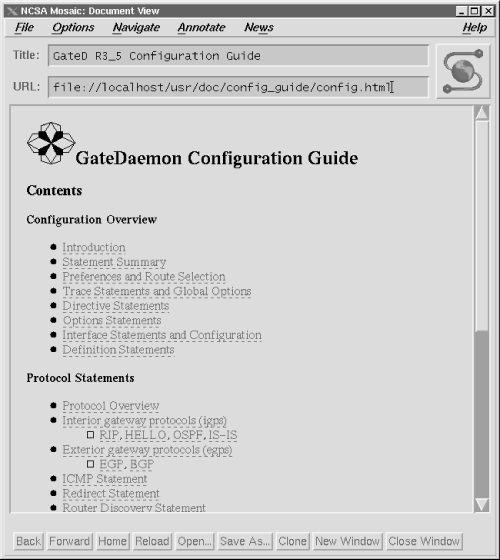
A Web browser can be used to view local hypertext files. This is how the gated documentation is delivered. Figure 13.2 shows a network administrator reading the gated documentation. The URL in Figure 13.2 is file://localhost/usr/doc/config_guide/config.html . The service is file , which means that the resource is to be read via the standard filesystem. The server is the local host ( localhost ). The path is /usr/doc/config_gated , and the file is config.html .
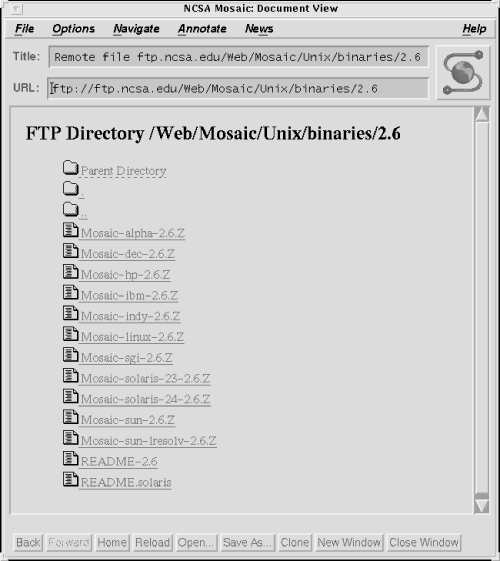
Another browser service that is often used by a network administrator is FTP. Figure 13.3 shows a network administrator using a browser to download software. The URL in Figure 13.3 is ftp://ftp.ncsa.edu/Web/Mosaic/Unix/binaries/2.6 . FTP is the service used to access the resource, which in this case is a binary file. The server is ftp.ncsa.edu , which is the anonymous FTP server at the National Center for Super Computing Applications. The path is /Web/Mosaic/Unix/binaries/2.6 and the file is any of the files listed on the screen.
Reading important announcements and documentation and downloading files are probably the most common uses a network administrator has for a Web browser. There are, however, many other things that can be done with a browser and a huge number of resources available on the network. A detailed discussion of browsers and the Web is beyond the scope of this book. See The Whole Internet User's Guide and Catalog , by Ed Krol (O'Reilly & Associates), for a full treatment of these subjects.
The browser provides a consistent interface to a variety of network services. But it is not the only way, or necessarily the best way, to access all of these services. In particular, it may not be the fastest or most efficient way to download a file. Figure 13.3 shows a file being downloaded from an anonymous FTP server. An alternative is to invoke ftp directly from the command-line interface.
|
|

|
|
| 12.9 Summary |
|
13.2 Anonymous FTP |