
|
Chapter 7 Backups |

|

|
|
Chapter 7 Backups |
|
A backup strategy describes how often you back up each of your computer's partitions, what kinds of backups you use, and for how long backups are kept. Backup strategies are based on many factors, including:
How much storage the site has
The kind of backup system that is used
The importance of the data
The amount of time and money available for conducting backups
Expected uses of the backup archive
In the following sections, we outline some typical backup strategies for several different situations.
Most users do not back up their workstations on a regular basis: they think that backing up their data is too much effort. Unfortunately, they don't consider the effort required to retype everything that they've ever done to recover their records.
Here is a simple backup strategy for users with PCs or stand-alone workstations:
Once a month, or after a major software package is installed, back up the entire system. At the beginning of each year, make two complete backups and store them in different locations.
Back up current projects and critical files with specially written Perl or shell scripts. For example, you might have a Perl script that backs up all of the files for a program you are writing, or all of the chapters of your next book. These files can be bundled and compressed into a single tar file, which can often then be stored on a floppy disk or saved over the network to another computer.
If your system is on a network, write a shell script that backs up your home directory to a remote machine. Set the script to automatically run once a day, or as often as is feasible. But beware: if you are not careful, you could easily overwrite your backup with a bad copy before you realize that something needs to be restored. Spending a few extra minutes to set things up properly (for example, by keeping three or four home-directory backups on different machines, each updated on a different day of the week) can save you a lot of time (and panic) later.
This strategy never uses incremental backups; instead, complete backups of a particular set of files are always created. Such project-related backups tend to be incredibly comforting and occasionally valuable.
Keep the monthly backups two years. Keep the yearly backups forever.
If you wish to perform incremental backups, you can improve their reliability by using media rotation. In implementing this strategy, you actually create two complete sets of backup tapes, A and B. At the beginning of your backup cycle, you perform two complete dumps, first to tape A, and then on the following day, to tape B. Each day you perform an incremental dump, alternating tapes A and B. In this way, each file is backed up in two locations. This scheme is shown graphically in Figure 7.2 .
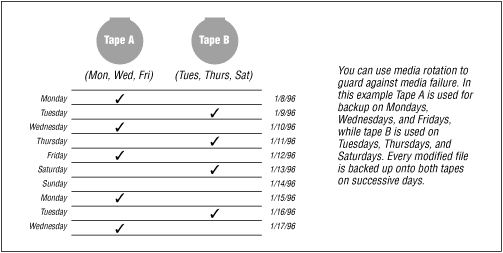
Most small groups rely on a single server with up to a few dozen workstations. In our example, the organization has a single server with several disks, 15 workstations, and DAT tape backup drive.
The organization doesn't have much money to spend on system administration, so it sets up a system for backing up the most important files over the network to a specially designed server.
|
Server configuration |
Drive #1: /, /usr, /var (standard UNIX filesystems) |
|
|
Drive #2: /users (user files) |
|
|
Drive #3: /localapps (locally installed applications) |
|
Client configuration |
Clients are run as "dataless workstations" and are not backed up. Most clients are equipped with a 360MB hard disk, although one client has a 1GB drive. |
Once a month, each drive is backed up onto its own tape with the UNIX dump utility. This is a full backup, also known as a level 0 dump.
Once a week, an incremental backup on drive #1 and drive #3 is written to a DAT tape (Level 1 dump). The entire /users filesystem is then added to the end of that tape (Level 0 dump).
A Level 1 dump on drive #2 is written to a file which is stored on the local hard disk of the client equipped with the 1GB hard drive. The backup is compressed as it is stored.
Every hour, a special directory, /users/activeprojects , is archived in a tar file. This file is sent over the network to the client workstation with the 1GB drive. The last eight files are kept, giving immediate backups in the event that a user accidentally deletes or corrupts a file. The system checks the client to make sure that it has adequate space on the drive before beginning each hourly backup.
The daily and hourly backups are done automatically via scripts run by the cron daemon. All monthly and weekly backups are done with shell scripts that are run manually. The scripts both perform the backup and then verify that the data on the tape can be read back, but the backups do not verify that the data on the tape is the same as that on the disk. (No easy verification method exists for the standard UNIX dump/restore programs.)
Automated systems should be inspected on a routine basis to make sure they are still working as planned. You may have the script notify you when completed, sending a list of any errors to a human (in addition to logging them in a file).
NOTE: If data confidentiality is very important, or if there is a significant risk of packet sniffing, you should design your backup scripts so that unencrypted backup data is never sent over the network.
Kept for a full calendar year. Each quarterly backup is kept as a permanent archive for a few years. The year-end backups are kept forever.
Kept on four tapes, which are recycled each month. These tapes should be thrown out every five years (60 uses), although the organization will probably have a new tape drive within five years that uses different kinds of tapes.
One day's backup is kept. Each day's backup overwrites the previous day's.
Most large decentralized organizations, such as universities, operate networks with thousands of users and a high degree of autonomy between system operators. The primary goal of the backup system of these organizations is to minimize downtime in the event of hardware failure or network attack; if possible, the system can also restore user files deleted or damaged by accident.
|
Server configuration |
|
|---|---|
|
Primary servers |
Drive #1: /, /usr, /var (standard UNIX filesystems) |
|
|
Drives #2-5: user files |
|
Secondary server (matches each primary) |
Drive #1: / , /usr, /var (standard UNIX filesystems) |
|
|
Drives #2-6: Backup staging area |
|
Client configuration |
Clients are run as "dataless workstations" and are not backed up. Most clients are equipped with a 500MB hard disk. The clients receive monthly software distributions from a trusted server, by CD- ROM or network. Each distribution includes all files and results in a reload of a fresh copy of the operating system. These distributions keep the systems up to date, discourage local storage by users, and reduce the impact (and lifetime) of Trojan horses and other unauthorized modifications of the operating system. |
Every night, each backup staging area drive is erased and then filled with the contents of the matching drive on its matching primary server. The following morning, the entire disk is copied to a high-speed 8mm tape drive.
Using special secondary servers dramatically eases the load of writing backup tapes. This strategy also provides a hot replacement system should the primary server fail.
Backups are retained for two weeks. During that time, users can have their files restored to a special "restoration" area, perhaps for a small fee. Users who wish archival backups for longer than two weeks must arrange backups of their own. One of the reasons for this decision is privacy: users should have a reasonable expectation that if they delete their files, the backups will be erased at some point in the future.
Many banks and other large firms have requirements for minimum downtime in the event of a failure. Thus, current and complete backups that are ready to go at a moment's notice are vital. In this scheme, we do not use magnetic media at all. Instead, we use a network and special disks.
Each of the local computers uses RAID (Redundant Arrays of Independent Storage) for local disk. Every write to disk is mirrored on another disk automatically, so the failure of one has no user-noticeable effects.
Meanwhile, the entire storage of the system is mirrored every night at 2 a.m. to a set of remote disks in another state (a hot site) . This mirroring is done using a high-speed, encrypted leased network line. At the remote location, there is an exact duplicate of the main system. During the day, a running log of activities is kept and mirrored to the remote site as it is written locally.
If a failure of the main system occurs, the remote system is activated. It replays the transaction log and duplicates the changes locally, and then takes over operation for the failed main site.
Every morning, a CD-ROM is made of the disk contents of the backup system, so as not to slow actual operations. The contents are then copied, and the copies sent by bonded courier to different branch offices around the country, where they are saved for seven years. Data on old tapes will be migrated to new backup systems as the technology becomes available.
The key to deciding upon a good strategy for backups is to understand the importance and time-sensitivity of your data. As a start, we suggest that answers to the following questions will help you plan your backups:
How quickly do you need to resume operations after a complete loss of the main system?
How quickly do you need to resume operations after a partial loss?
Can you perform restores while the system is "live?"
Can you perform backups while the system is "live?"
What data do you need restored first? Next? Last?
Of the users you must listen to, who will complain the most if their data is not available?
What will cause the biggest loss if it is not available?
Who loses data most often from equipment or human failures?
How many spare copies of the backups must you have to feel safe?
How long do you need to keep each backup?
|
|

|
|
| 7.1 Make Backups! |
|
7.3 Backing Up System Files |